크롬/익스플로러 창으로 연 온라인 PDF 문서
PDF 문서 안에 있는 테이블을 Pandas DataFrame으로 읽어오기
tabula-py를 pip 설치 후 간단한 코드로 읽어오기 가능
2019년 12월 10일, 온라인 PDF 테이블 추출하기
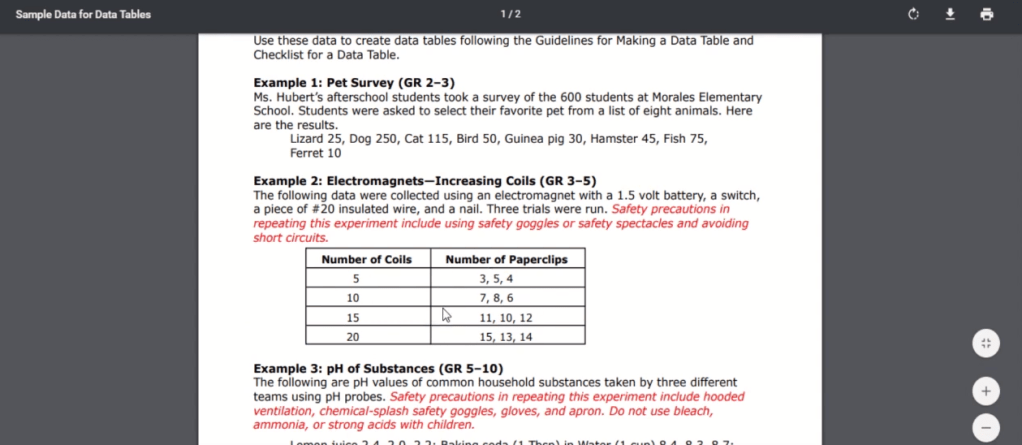
2019년 12월 둘째 주 소식을 전합니다.
이미 잘 알고 사용하시는 사용자분들도 계시겠지만, 이번 주는 유투브에 올라온 영상 하나를 번역, 요약하여 소개하려고 합니다. 비록 짧고 쉬운 내용이지만 많은 연구자분들의 수고를 덜어줄 내용이라고 생각합니다.
이 영상은 구글 크롬이나 MS 익스플로러 창으로 연 온라인 PDF 문서에 있는 테이블을 Pandas의 DataFrame 오브젝트로 뽑아내는 방법을 소개한 영상입니다. Pandas는 파이썬 사용자라면 모르는 사람이 없을 정도로 잘 알려진 데이터 분석과 핸들링용 패키지입니다.
구글 스칼라에서 논문 검색을 하다보면 필수적으로 맞닥뜨리는 것이 바로 PDF 문서의 테이블입니다. 그리고 대학원생이나 논문을 준비중인 직장인이라면 한번 쯤, 참고하고 있는 논문 데이터를 그냥 Pandas 데이터프레임으로 한번에 뽑아내고 싶다는 생각을 해보셨을 것입니다. 저도 그랬었구요.
일단 원본 영상 링크입니다. 유투브에 그냥 공개된 영상이라 퍼와도 될 거라고 생각하는데, 혹시 문제가 된다면 댓글이나 메일로 제작자에게 허락을 구할까 합니다.
- 패키지 Dependencies 설치
준비물은 파이썬, 파이썬에 설치된 Pandas 패키지, 테이블이 있는 PDF 문서입니다. 먼저 추출을 위해 필요한 패키지를 설치합니다.
시간이 없으신 개발자/분석가 분들은 주황색으로 작성한 부분은 스킵하세요.
제가 이 블로그를 운영하면서 스스로 다짐한 것 중 하나는 “친절하게 쓰자”입니다. “모든 것을 다” 설명하자는 것은 아니지만, 최소한 개발자들의 귀차니즘으로 인해 파이썬에 막 입문한 비개발자 입장에서 보면 2계단, 3계단 생략된 설명은 지양하자는 것이 개인적인 소망입니다.
파이썬 개발자분들은 알아서 이 부분을 스킵하시리라고 믿고 설명을 계속합니다. 파이썬이 PDF문서의 테이블을 추출하려면 파이썬에 tabula-py라는 라이브러리가 설치되어 있어야 하며 이를 pip이라는 파이썬 라이브러리 인스톨 도우미(=다른 패키지를 설치하기 위해 존재하는 패키지)를 사용합니다.
관리자 권한을 획득한 채 cmd창을 연 다음, cmd창에서 파이썬이 설치되어 있는 디렉토리(python.exe 또는 python3.exe가 존재하는 디렉토리)로 이동합니다. 커스톰 설치 환경과 리눅스 환경에서 사용하시는 분들을 위한 설명은 과감히 생략합니다(이미 지식이 풍부한 개발자라고 믿고 생략합니다).
그 다음 다음 명령어를 사용해 tabula-py를 설치합니다:
- pip install tabula-py
혹시 설치 과정에서 에러가 난다면 위 “pip으로 tabula-py 설치” 스크린샷을 참고하여 numpy, distro, pytz, python-dateutil, six 등 Dependencies 패키지 설치 여부와 버전을 확인하세요.
- 스크립트 작성
이제 파이썬 IDE(또는 파이썬 코드를 작성할 수 있는 창)을 열어 아래와 같이 작성합니다.

온라인 리퀘스트를 위해 SSL 패키지도 같이 import하는 것으로 보입니다. URL 변수에 테이블을 추출하고 싶은 PDF 문서가 열려있는 웹 주소를 줍니다. 코드를 작성한 후 이를 터미널에서 실행합니다(cmd창에서 python 스크립트 파일명.py 실행).
- 실행 및 결과 확인
코드를 보시면 아시겠지만 별 문제 없다면, PDF 파일에서 읽어온 테이블을 Pandas DataFrame 오브젝트인 df 변수로 읽어올 수 있을 것입니다.
“별 문제 없다면 ” 이라고 강조한 이유는, 그 동안 수 많은 파이썬 튜토리얼과 기술 문서를 따라하면서 온갖 이유(Python2 vs Python3 설정, Environment 설정, Dependencies 설정, 패키지 변경 등)로 인해 매우 쉽고 간단한 코드가 실행되지 않은 것을 보아왔기 떄문입니다. 또 이를 해결하기 위해 이보다 훨씬 더 기술적으로 어려운 것을 공부하며 온갖 노가다와 고생을 해본 경험은 비단 저만의 것이 아니리라고 믿습니다. 참고로 저는 옛날 일이긴 하지만, 하나의 텐서플로우 튜토리얼을 따라해 결과를 그대로 재현하기 위해 GPU 드라이버를 재설치하고 2시간 넘게 깃허브 댓글을 뒤진 경험이 있습니다.
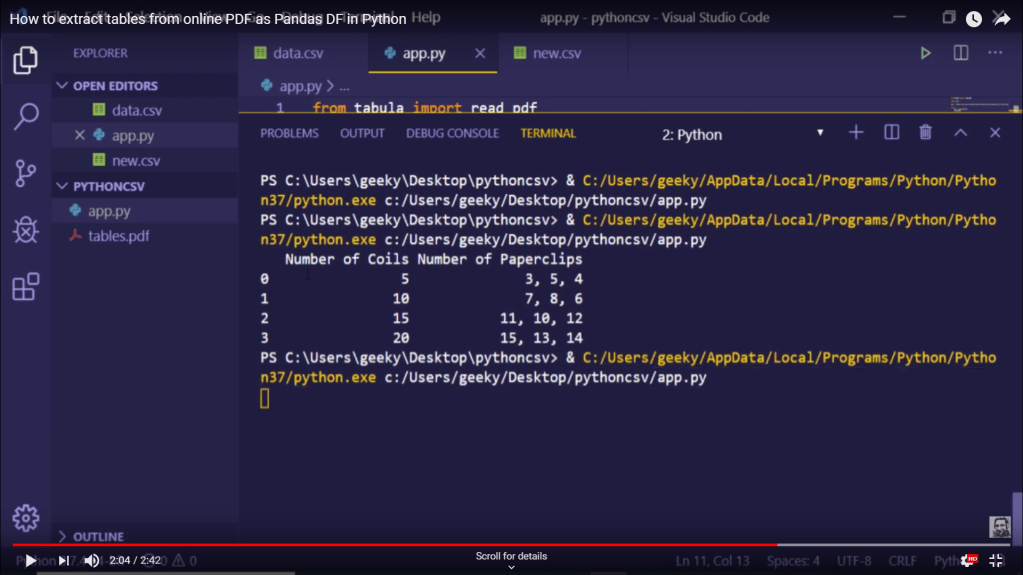
다시 한번 별 문제 없다면, 코드의 print(df) 명령이 실행되어 PDF 문서에 있는 테이블이 터미널에 잘 출력된 것을 보실 수 있습니다. 만약 PDF 문서에 테이블이 여러 개 있다면 여러 개의 테이블을 읽어온다고 하며, 그 여러 DataFrame들을 어떤 식으로 불러오는지는 최근 포맷한 제 개인 PC에 파이썬을 다시 설치하기 귀찮은 관계로? 확인하지 않았습니다.
