특별히 전달할 소식이 없을 때에는 캐글(kaggle) 분석 과제 뽀개기를 해보려고 합니다. 먼저 캐글의 hello world에 해당하는 타이타닉 생존자 예측입니다. 모든 코드는 Google Colab Jupyter Notebook 환경에서 작성한 것입니다.
from google.colab import files
!pip install -q kaggle
uploaded = files.upload()
#kaggle.json 파일 업로드 (kaggle 로그인 후 MyPage에서 다운로드 받을 수 있음
!mkdir /root/.kaggle
!mv kaggle.json /root/.kaggle/
!kaggle competitions download -c titanic
!pip install --upgrade pandas_profiling
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas_profiling import ProfileReport
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
print(train.shape)
print(test.shape)
#간단하게 EDA하기 위해 PandasProfiling 사용
rp_train = ProfileReport(train, title='Train', html={'style':{'full_width':True}})
rp_test = ProfileReport(test, title='Test', html={'style':{'full_width':True}})
rp_train.to_file('rp_train.html')
files.download('rp_train.html')
rp_test.to_file('rp_test.html')
files.download('rp_test.html')
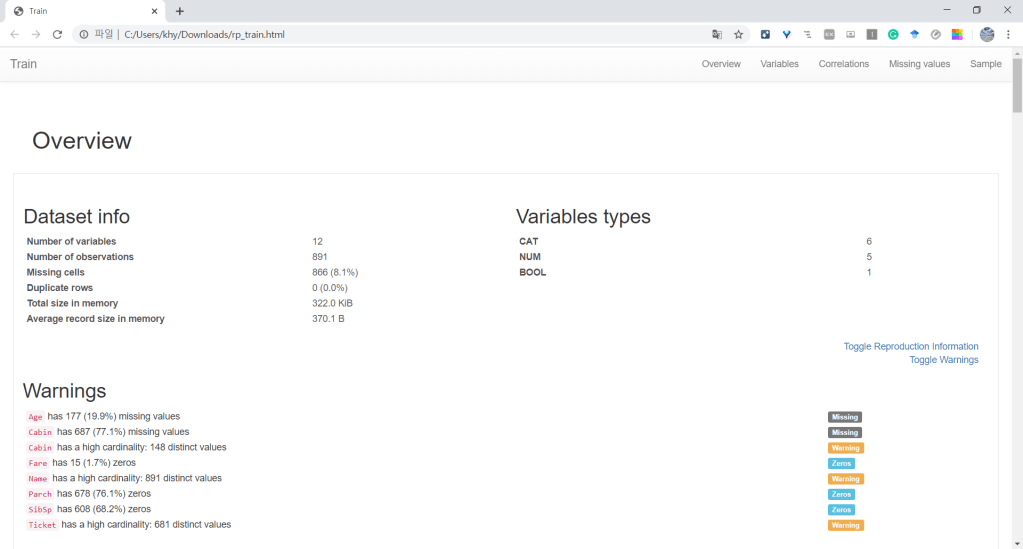
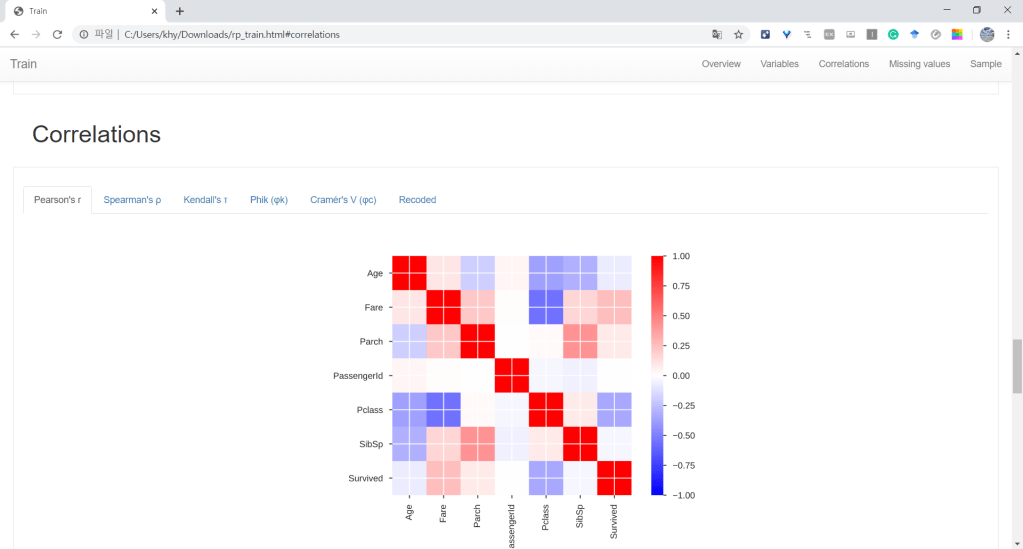
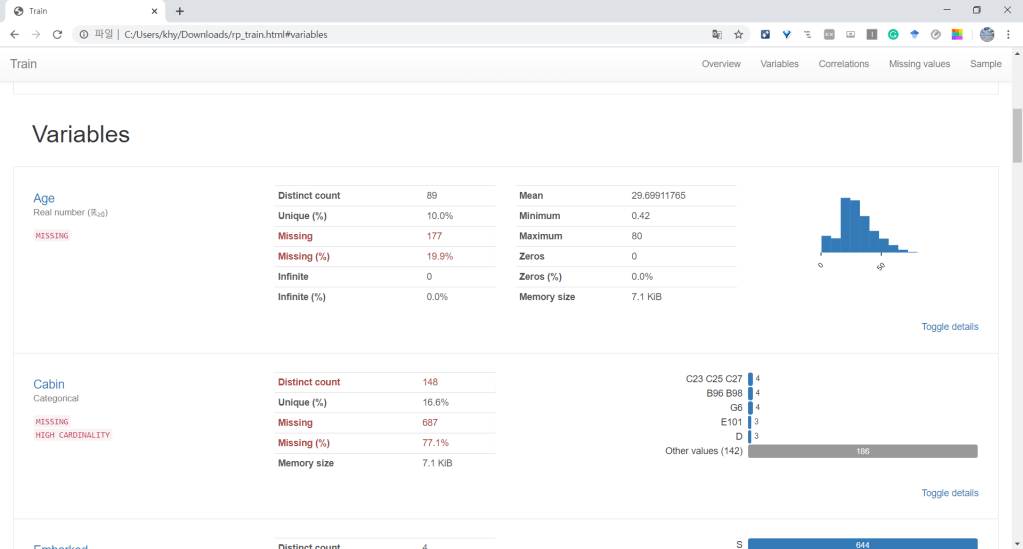
워드프레스 가입형은 유료 플랜은 너무 비싸고 무료는 제한이 너무 많습니다. 대표적인 것이 바로 플러그인/사용자 CSS 레이아웃 사용 불가. 외부 HTML 보여주는 기능도 제한이 있어 Google Colab을 HTML로 보여줄 수 없습니다. 그래서 이미지 파일로…………….. 조만간 설치형으로 호스팅할 것입니다.
EDA 해석
- NA값은 Age(training), Cabin(training, test), Fare(test)에 존재
- Parch, SibSp는 값이 0에 skew되어 있음 (상당 수가 혼자 탄 승객임)
- 상관분석 결과를 보면 Survived와 가장 높은 상관관계를 지닌 변수는 Fare(Pclass), Parch, Sex임.
- Parch는 값이 0에 많이 쏠려있으므로 제외. -> Sex, Pclass, Fare
#추가 EDA - categorical variables
#Sex
sex_pivot = train.pivot_table(index='Sex', values='Survived')
print(sex_pivot)
sex_pivot.plot.bar(ylim=(0,1))
plt.plot()
#추가 EDA - continuous variable
survived = train[train['Survived']==1]
failed = train[train['Survived']==0]
#Fare
survived['Fare'].plot.hist(alpha=0.3, color='red', bins=100, figsize=(20,10))
failed['Fare'].plot.hist(alpha=0.3, color='blue', bins=100, figsize=(20,10))
plt.legend(['Survived', 'Failed'])
plt.show()
#Age
survived['Age'].plot.hist(alpha=0.3, color='red', bins=100, figsize=(20,10))
failed['Age'].plot.hist(alpha=0.3, color='blue', bins=100, figsize=(20,10))
plt.legend(['Survived', 'Failed'])
plt.show()
#Age를 구간별로 짜르면 class 구분이 가능한 bin이 존재함을 확인(예:0~5살 영유아 구간은 Survived 비율이 높음)
EDA 결론으로 Pclass(CAT), Fare(NUM), Sex(CAT), Age(NUM)의 4가지 변수를 모델에서 사용하기로 선택
#Cleansing & Mangling
#Processing with Age in training set
#Age는 임의의 구간이 아닌, 의미가 명확한 구간으로 나눌 수 있는 명목변수이다.
#따라서 CAT 변수로 바꿀 수 있다: Age_categories: CAT
#Age는 미싱값이 있다. 미싱값도 하나의 CATEGORY로 변환해서 사용한다
def process_age(df,cut_points,label_names):
df["Age"] = df["Age"].fillna(-0.5)
df["Age_categories"] = pd.cut(df["Age"],cut_points,labels=label_names)
return df
cut_points = [-1,0, 5, 12, 18, 35, 60, 100]
label_names = ["Missing", 'Infant', "Child", 'Teenager', "Young Adult", 'Adult', 'Senior']
train = process_age(train,cut_points,label_names)
test = process_age(test,cut_points,label_names)
age_cat_pivot = train.pivot_table(index="Age_categories",values="Survived")
age_cat_pivot.plot.bar()
plt.show()
#Processing with Fare in test set
#Fare는 Age와 달리 의미 있는 구간으로 나누기 위한 정보가 부족하다. (물가, 소득수준 등)
print(test[test['Fare'].isna()==True])
#동일한 Pclass, Sex, Age_categories 값을 지닌 row들의 mean(Fare)를 사용하기로 하자.
#test셋에는 해당 데이터가 자기 자신밖에 없다. train 셋에서 찾아보자
subset0 = train[(train['Pclass']==3) & (train['Sex']=='male') & (train['Age_categories']=='Senior')]
print(subset0)
#위 subset Fare의 평균값을 na값을 대체하여 사용
test['Fare'].fillna(subset0.Fare.mean(), inplace=True)
print(test.iloc[152])
print()
#잘 replace 되었나 체크
print(test[test['Fare'].isna()==True])
#카테고리컬 variable을 One-hot 인코딩
def create_dummies(df, c_name):
dummies = pd.get_dummies(df[c_name], prefix=c_name)
df = pd.concat([df,dummies], axis=1)
return df
train_dummies = create_dummies(train, "Pclass")
test_dummies = create_dummies(test, "Pclass")
train_dummies = create_dummies(train_dummies, "Sex")
test_dummies = create_dummies(test_dummies, "Sex")
train_dummies = create_dummies(train_dummies, "Age_categories")
test_dummies = create_dummies(test_dummies, "Age_categories")
train_dummies.sample(5)
test_dummies.sample(5)
#Fare 정규화
#트레이닝셋
from sklearn.preprocessing import MinMaxScaler
minmax_scaler = MinMaxScaler()
fitted = minmax_scaler.fit_transform(train_dummies[['Fare']])
train_dummies['Fare_norm']= fitted
print(train_dummies.sample(5))
print();print()
#테스트셋
fitted = minmax_scaler.fit_transform(test_dummies[['Fare']])
test_dummies['Fare_norm']= fitted
print(test_dummies.sample(5))
#Fare 정규화
#트레이닝셋
from sklearn.preprocessing import MinMaxScaler
minmax_scaler = MinMaxScaler()
fitted = minmax_scaler.fit_transform(train_dummies[['Fare']])
train_dummies['Fare_norm']= fitted
print(train_dummies.sample(5))
print();print()
#테스트셋
fitted = minmax_scaler.fit_transform(test_dummies[['Fare']])
test_dummies['Fare_norm']= fitted
print(test_dummies.sample(5))
#머신러닝 모델 만들기
#EDA 결과 독립-종속 간 선형성 확인 가능했다. 로지스틱 회귀 모델(glm)으로 테스트
columns = ['Fare_norm', 'Pclass_1', 'Pclass_2', 'Pclass_3', 'Sex_female', 'Sex_male',
'Age_categories_Missing','Age_categories_Infant',
'Age_categories_Child', 'Age_categories_Teenager',
'Age_categories_Young Adult', 'Age_categories_Adult',
'Age_categories_Senior']
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
from sklearn.model_selection import train_test_split
all_X = train_dummies[columns]; all_y = train_dummies['Survived']
#training, validation셋 분할
train_X, valid_X, train_y, valid_y = train_test_split(all_X, all_y, test_size=0.2, random_state=0)
print(train_X.shape)
print(valid_X.shape)
print(train_y.shape)
print(valid_y.shape)
print()
print(train_X.info())
lr.fit(train_X, train_y)
pred = lr.predict(valid_X)
from sklearn.metrics import accuracy_score, confusion_matrix
acc = accuracy_score(valid_y, pred)
conf_mat = confusion_matrix(valid_y, pred)
print(acc)
print()
print(pd.DataFrame(conf_mat, columns=['Survived_Pred','Died_Pred'], index=[['Survived_True','Died_True']]))
print()
#10-fold validation learning
from sklearn.model_selection import cross_val_score
import numpy as np
scores = cross_val_score(lr, all_X, all_y, cv=10)
print(scores)
print()
print(np.mean(scores))
선형모델로 80%면 뭐 나쁘진 않습니다… 이대로 test셋을 예측해봅니다.
# test셋 예측
lr_test = LogisticRegression()
lr_test.fit(all_X, all_y)
test_X = test_dummies[columns]
test_pred = lr_test.predict(test_X)
print(test_pred)
비선형모델을 돌려보는 것과 추가로 Feature Engineering하는 과정(Name 변수 데이터를 Parsing하여 직업, 사회적 직위와 같은 변수를 생성)은 생략합니다. 다음에는 Housing Price Prediction을 올려보겠습니다.
