ELECTRA: GAN의 개념으로 MLM과 LM의 장점 결합
BERT 시리즈와 맞먹는 성능, 훨씬 더 효율적인 컴퓨팅
TF로 공개, 영어 모델만 지원
2019년 3월 13일, 모습을 드러낸 NLU 신형엔진

들어가며…
전 세계가 코로나로 어수선하고 실리콘밸리마저 시장 붕괴에 대한 공포감에 휩싸이는 가운데, 개인적으로 이번 2월은 프리랜서에서 정규직 테크니컬 라이터로 전환하기에 바쁜 한 달이었습니다. 곧 직장에서 열심히 일할 예정인지라 다시 최선을 다해 연재하려고 합니다.
3월의 첫 소식으로 구글에서 기존 NLU 모델보다 훨씬 더 효율적이면서도 좋은 성능을 자랑하는 ELECTRA라는 모델을 공개했다는 내용을 전합니다. 이 포스팅은 구글 AI 블로그에 있는 내용을 번역/해설하여 공유하는 것입니다. 이 블로그의 특성상 상업적 이용 따위는 현재 전혀 고려하고 있지 않지만 차후 문제가 있을 경우 삭제하겠습니다.
ELECTRA 모델을 짧게 요약하면, 작은 BERT(Bidirectional Encoder Representations from Transformers)로 어떤 문장을 생성(Generate)하고 별도의 Transformer 모델로 이 문장 속에 있는 모든 단어를 검증(Discriminate)함으로써 Masked Words(BERT의 15% subset)만 검증하던 BERT에 비해 훨씬 더 sample-efficient한 학습이 가능한 모델입니다. 눈치채셨겠지만 이는 GAN(Generative Adversarial Network)의 Generator/Discriminator 구조를 빌려온 것이라고 합니다.
원문:More Efficient NLP Model Pre-training with ELECTRA 게재일:Tuesday, March 10, 2020 원문링크:https://ai.googleblog.com/ 원 논문링크:https://openreview.net/forum?id=r1xMH1BtvB 저자: Kevin Clark, Student Researcher and Thang Luong, Senior Research Scientist, Google Research, Brain Team
ELECTRA: 더 효율적인 NLP 사전학습 모델
최근 BERT, RoBERTa, XLNet, ALBERT, T5 등 최신 사전학습(Pre-training) 기법이 개발되면서 NLP 분야에는 큰 진전이 있었습니다.
이 기법들은 서로 조금씩 다른 구조를 갖고 있지만, 공통적으로 대규모 텍스트 데이터를 비지도학습(Unsupervised Learning)하여 인간 언어를 넓고 깊게 표현할 수 있는 언어 모델(General Language Model)을 만든 다음 이를 특정한 NLP 분야(감성 분석, Q&A)에 baseline model로 사용하기 위해 만들어졌습니다.
기존 사전학습 기법은 크게 2가지로 나뉩니다: LM(Language Model)과 MLM(Masked Language Model)입니다.
LM은 한 문장에 있는 단어들을 첫 단어부터 끝 단어까지 하나씩 차례대로 학습하면서 ‘지금까지 학습한 단어들의 맥락을 고려할 때 이 다음 단어는 무엇이 와야 할까?’라는 개념으로 인간 언어를 학습합니다(e.g> GPT).
MLM은 한 문장에 있는 단어들을 차례대로 학습하는 것이 아니라 양방향(문장 시작 단어부터 끝 단어 방향으로, 또한 끝 단어부터 시작 단어 방향으로)으로 학습하면서 마스킹처리(Masked out, 모델이 인간 문장을 이해해서 단어를 예측하도록 “가려놓은” 일부 단어들)된 일부 단어들을 예측하는 모델입니다. MLM 방식으로는 BERT, RoBERTa, ALBERT 등 BERT 시리즈가 있습니다.
MLM은 양방향(bi-directional) 학습이 가능하므로 문장의 첫 단어부터 끝 단어까지 순서대로 문장 맥락을 이해하는 것이 아니라, 맥락을 문장 전체를 토대로 이해해가며 인간 언어를 학습한다는 장점이 있습니다. 하지만 MLM은 LM처럼 문장 내 모든 단어를 예측하는 것이 아니라 마스킹된 단어만 예측합니다. MLM은 문장 내 뚫린 구멍(마스킹된 일부 단어)을 메꾸면서(메꾸고 틀리고 다시 메꾸고 틀리고 다시 메꾸기를 반복하면서…) 인간 언어를 이해하므로, 뚫린 구멍에 위치해있던 단어들만 학습에 사용되고 나머지 단어들은 버려집니다.
이 마스킹된 단어가 전체 단어에서 차지하는 비율은 BERT에서는 15%로 알려져 있으며 때문에 BERT에서는 전체 텍스트 데이터(단어 수 기준)의 15%만이 학습에 사용됩니다.

구글 연구진이 개발한 ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)는 BERT의 장점을 유지하면서도 훨씬 더 효율적으로 학습하는 모델입니다. ELECTRA는 동일한 컴퓨팅 자원으로 다른 모델보다 압도적인 성능을 보입니다.
예를 들어 ELECTRA는 GLUE 벤치마크에서 RoBERTa, XLNet과 동일한 성능을 기록하면서도 겨우 25%의 컴퓨팅 리소스만 사용합니다. 또 SQuAD Q&A 벤치마크에서는 최고 성능을 기록했습니다. 단일 GPU 환경에서 몇 일 동안 학습한 ELECTRA는 30배 이상 더 많은 컴퓨팅 리소스를 잡아먹는 GPT보다 더 높은 정확도를 보입니다.
ELECTRA는 TensorFlow 기반 오픈소스로써 릴리즈되고 있으며 사용가능한 pre-trained LM을 제공합니다.
사전학습을 더 빠르게!
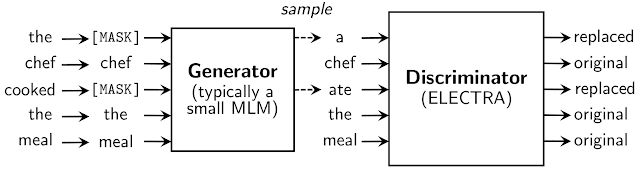
ELECTRA는 RTD(Replaced Token Detection)이라는 새로운 사전학습 기법을 사용합니다. RTD는 MLM처럼 양방향 학습을 하면서도 LM처럼 문장 내에 모든 단어를 학습에 사용합니다. ELECTRA는 GAN과 비슷하게 “진짜”와 “가짜” 데이터를 구별하기 위한 학습을 합니다.
ELECTRA는 BERT처럼 문장 내 일부 토큰(단어)을 “[MASK]”로 표시하는 방식으로 마스킹하는 것이 아니라 이들을 “가짜” 단어로 바꿔치기 합니다. 예를 들어 데이터셋에 있는 원래 문장이 “The chef cooked the meal.”라면 “cooked”를 “[MASK]”로 표시하는 것이 아니라 “ate”로 바꿔치기할 수 있습니다. “ate”로 바꾸면 문장이 말이 되긴 하지만 본래 텍스트 데이터셋에서 말하고자 했던 맥락과는 차이가 있습니다.
일부 단어를 가짜 단어로 바꿔치기 했다면, Discriminator(판별자) 신경망 모델이 이 문장 내 모든 단어를 살펴보면서 바꿔치기한 단어(“가짜”)가 무엇이고 원래 데이터셋에 있던 단어(“진짜”)가 무엇인지 판단합니다(Binary Classification). 즉, Discriminator는 모든 단어에 대해 바꿔치기 여부를 판단하면서 판단 정확도가 높아지는 방향으로 학습을 합니다. 따라서 모든 단어를 학습하기 때문에 15%만 사용하는 BERT보다 훨씬 sample-efficient하며 결과적으로 동일한 성능을 더 적은 데이터만으로 달성합니다. 동시에 ELECTRA Discriminator 모델이 진짜/가짜 판단 정확도를 올리기 위해서는 데이터셋에 담긴 언어 맥락을 정확하게 이해해야 하므로(the accurate representation of the data distribution) 인간 언어 표현 측면에서도 훌륭한 성능을 갖게 됩니다.

일부 토큰을 가짜로 바꿔치기 하려면 먼저 가짜 단어를 생성해야 합니다. 가짜 단어는 Generator라는 다른 신경망 모델이 생성합니다. 전체 토큰셋에 대하여 특정 확률분포를 따라 토큰을 생성하는 모델이라면 무엇이든 Generator가 될 수 있습니다. 구글 연구진은 Generator로 작은 히든 사이즈를 가진 BERT를 사용했고 이 Generator는 Discriminator와 함께 학습되었습니다.
Generator가 데이터를 Discriminator에 보내는 Generator/Discriminator 구조는 GAN과 유사하지만, Generator는 마스킹된 단어를 예측하기 위해 최대우도(maximum likelihood) 학습을 한다는 차이가 있습니다.
역자 추가 해설: 위 내용을 추가로 조금 쉽게 풀어 설명하겠습니다. GAN은 학습과정에서 Discriminator가 Generator에게 피드백을 전달합니다. 즉, Discriminator가 진짜/가짜이미지를 더 잘 구별하기 위해 데이터를 학습하는 과정에서 얻은 지식(피드백)은 Generator에도 전달(Back-propagated)되어 Generator도 더 정교하게 Discriminator를 “속일 수” 있도록 진화합니다.
하지만, ELECTRA는 Generator 입장에서 자신이 샘플링한 가짜 단어들을 가지고 역전파 학습을 하기 어렵기 때문에(원 논문 13페이지 참조) Discriminator가 Generator에게 피드백을 주진 못합니다. ELECTRA에서 Generator는 어떤 문장이 주어지고 그 문장 내에서 일부 단어들이 “[MASK]”로 가려졌을 때, “[MASK]”를 대체하는 다른 단어를 특정한 확률분포를 따라 생성하는 모델입니다. 그리고 이 특정한 확률분포의 모수(Parameter)를 수정하여 “[MASK]”를 대체하는 단어로 원래 단어(=”진짜” 단어)를 생성하도록 하는 것이 목적입니다. 따라서 경사하강법을 사용해 “진짜” 단어를 생성할 확률(우도값)을 최대로 하는 최대우도 학습을 수행합니다.
Generator와 Discriminator는 같은 데이터를 입력으로 받습니다(동일한 워드 임베딩).사전 학습이 끝난 후 Generator는 버려지며 Discriminator가 ELECTRA 본 모델로써 다른 NLP 작업(감성분석, Q&A)의 베이스 모델로 사용됩니다. Generator와 Discriminator 모두 Transformer 신경망 아키텍처를 사용합니다.
ELECTRA Results
ELECTRA를 사용한 결과 동일한 컴퓨팅 리소스가 주어졌을 때 다른 NLU 모델을 압도하는 성능을 보였습니다. 특히 RoBERTa, XLNet과 비교 시 25%의 리소스로 비슷한 성능을 보였습니다.
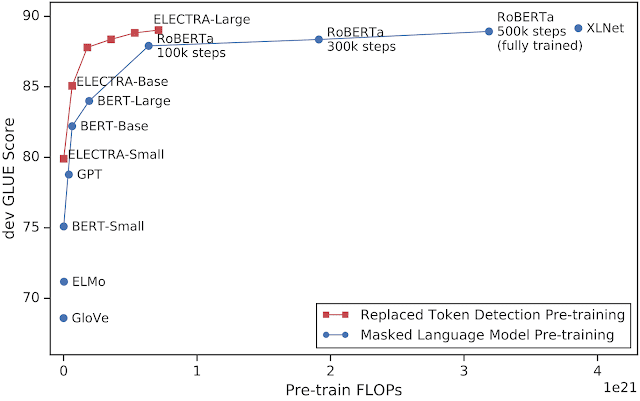
GLUE 점수에서 최상위를 차지하는 T5 (11B) 모델은 위 그림에 있지 않는데, T5가 RoBERTa 비교 시 10배 이상의 리소스를 잡아먹는 등 X축 상에서 T5가 소모하는 컴퓨팅 자원을 표시할 수 없기 때문입니다.
ELECTRA는 4일 동안 단일 GPU로만 학습하는 스몰스케일(small-scale) 환경에서도 좋은 정확도를 보였습니다. 여러 TPU(Tensor Processing Unit)를 사용할 때 보다 정확도는 낮지만 작은 리소스로 꽤나 괜찮은 성능을 보였으며 심지어 GPT에 필요한 계산량의 1/30만으로도 GPT를 압도하는 성능을 확인했습니다.
마지막으로, 대규모 스케일(RoBERTa와 동일한 리소스/T5의 10% 리소스)로 ELECTRA 모델을 만든 결과 단일 모델로는 SQuAD 2.0 Q&A 데이터셋에서 최고 기록을 경신했고, GLUE 점수에서 RoBERTa, XLNet, ALBERT를 추월했습니다. 아직 T5-11b모델이 GLUE에서 최고 기록을 가지고 있지만, ELECTRA의 크기는 T5의 1/30에 지나지 않으며 T5 계산량의 10%만을 사용합니다.
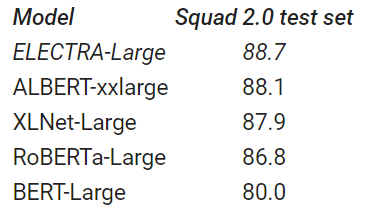
Releasing ELECTRA
구글은 ELECTRA 베이스 모델을 만드는 사전학습용 코드와 텍스트 분류, Q&A, 시퀀스태깅 등 세부작업을 위한 파인튜닝용 코드를 릴리즈합니다. 이 릴리즈는 단일 GPU에서 작은 스케일로 ELECTRA를 학습하기 위한 코드를 포함합니다. 또 ELECTRA-Large, ELECTRA-Base, ELECTRA-Small 각 모델에 대해 사전학습된 가중치 벡터도 공유합니다. ELECTRA는 현재 “영어” 모델만 지원하며 향후 다른 언어도 지원할 계획도 있습니다.
