OpenAI NLP 프레임워크 GPT-2를 사용한 텍스트 생성 (DeepFake Text)
생성한 텍스트와 코멘팅 봇으로 시민 의견 수렴 과정에 개입
로봇이 작성한 코멘트인지 아닌지 구별할 수 없음 (정확도 50% 미만)
캡차(CAPTCHA) 등 인증수단 강화 필요
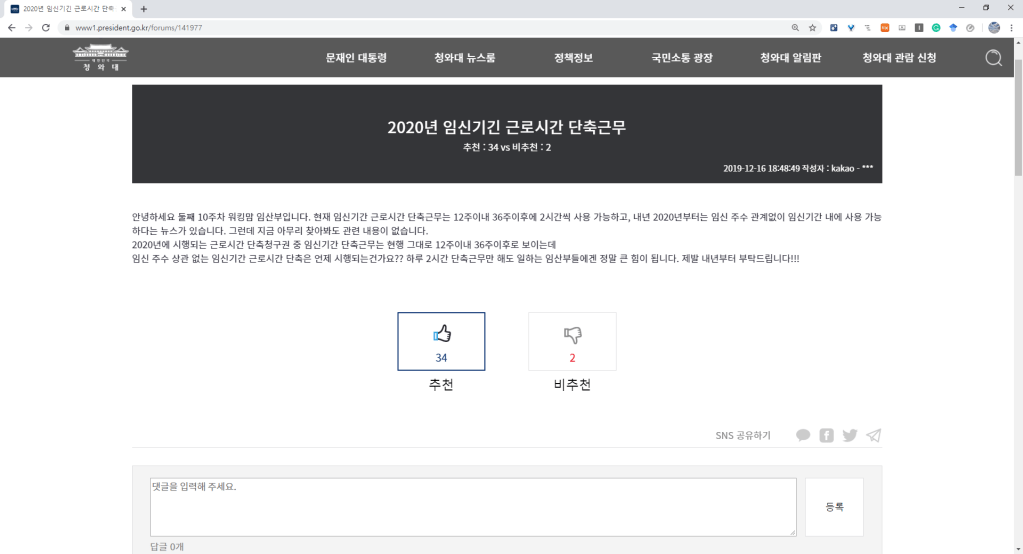
2019년 12월 31일, 여론 형성에 개입하는 DeepFake
행복한 2019년 마지막 주 되셨기를 바라며, 모두 새해에는 더 행복하고 기쁜 삶이 되시기를 바랍니다.
새해 첫날인 오늘, 12월 마지막 주 포스팅으로 인공지능이 우리 사회에 어떤 영향을 미칠 수 있는지와 관련해 논문 한 편을 요약, 번역해 소개합니다.
논문 제목: Deepfake Bot Submissions to Federal Public Comment Websites Cannot Be Distinguished from Human Submissions 게시일: 2019-12-18 게시처: Technology Science 저자: Max Weiss (A Senior at Harvard College) 링크: https://techscience.org/a/2019121801/
Abstract/Results 요약
미 연방 정부는 어떤 공공 정책을 시행할 때 댓글 업로드를 통해 여론을 수렴하는 시기를 둡니다. 그런데 이러한 여론 수렴 제도는 잘못된 의도를 가진 사람들에게 악용당하기 쉬운 구조를 갖고 있습니다.
2017년, 미 연방 통신위원회(이하 FCC)가 망 중립성(net neutrality) 폐지를 추진하는 과정에서 전체 댓글의 약 96%인 2,100만개의 댓글(총 댓글 수 약 2,200만개)가 비교적 단순한 방법인 치환법(Search-and-Replace)으로 생성된 문장임이 밝혀진 바 있습니다. 치환법이란, 기계로 문장을 생성하는 전통적인 방법 중 하나입니다. 사람이 만든 샘플 문장을 가지고 그 문장의 문맥은 그대로 유지되면서 문장을 구성하는 단어만 바꿔치는 방법으로 생성하는 방법입니다.
문제는, 치환법으로 만든 문장이 사람이 만든 문장인지 기계가 만든 문장인지 비교적 쉽게 구별이 가능했다면, 이제는 구분이 불가능한 방법으로 기계가 문장을 만들어내고 이를 댓글에 올릴 수 있다는 점입니다.
DeepFake 텍스트는 TensorFlow, OpenAI와 같이 누구나 사용할 수 있는 오픈소스 AI 도구로 만들 수 있으며, 이 연구에서는 사람이 과연 이러한 “가짜 여론”을 과연 기계가 쓴 것인지 아니면 사람이 쓴 것인지 구분할 수 있는가를 테스트했습니다.
이 연구에서는 OpenAI의 DeepFake NLP 프레임워크인 GPT-2를 사용해 기존의 연방 공공 정책 결정을 위한 여론 수렴에 사용되었던 댓글을 학습한 모델을 만들었습니다. 그리고 이 DeepFake 텍스트 생성 모델로 만든 가짜 댓글을 Proxy 서버, 웹봇을 사용해 2019년 10/26~30 기간 동안 진행된 연방 정책(Section 1115 Idaho Medicaid Reform Waiver: 미국 아이다호 주의 저소득층 의료급여 제공 조건을 완화하는 변경안)에 관한 여론 수렴 사이트에 업로드했습니다.
해당 기간에 여론 수렴 사이트에 업로드된 총 댓글 수는 1,810개였고, 그 중 DeepFake 모델로 만든 가짜 댓글 수는 1,001개로 전체의 약 55.3%을 차지했습니다.
그리고 108명으로 구성된 설문조사 대상을 구성해 이 가짜 댓글들과 사람이 실제로 쓴 댓글들을 섞어서 누가 쓴 글인지 구별할 수 있는가를 확인했습니다. 이들 108명은 전통적인 방식으로 작성한 기계 댓글을 잘 분별해낼 수 있는 능력을 가진 사람으로 구성했고, 적극적 참여를 위해 실험 참여와 더불어 글쓴이를 정확히 분별했을 경우 보상이 주어졌습니다.
실험 결과, 이들은 약 49.63%의 분별 정확도를 보여주었고 이는 임의로 선택한 정확도(50%)보다 낮은 수치이므로 사람은 DeepFake 모델로 만든 가짜 여론이 가짜인지 아닌지 정확히 분별하기 어렵다는 결론을 얻었습니다.
Data & Methodology & Else
인트로, 백그라운드 등은 생략하고 사용된 데이터, 도구, 방법론은 아래와 같습니다.
- 연방 공공 댓글 사이트(Federal public comment website, 여론 수렴 사이트)
- OpenAI GPT-2 NLP 프레임워크
- 트레이닝셋용(Training Data) 기존 공공 댓글
- 다른 주(아칸소, 알라바마, 애리조나, 인디아나 등)에서 마찬가지로 저소득층 의료급여 수급조건 완화 정책을 위해 만든 여론 수렴 사이트의 댓글을 Medicaid.gov에서 다운로드하여 사용
- 웹봇 및 프록시 서버
- 설문조사 도구(Qualtrics and Amazon Mechanical Turk Survey)
※ 웹봇 루틴(Web-bot Execution Routine)
- 가짜 댓글이 모두 다 입력될 때까지 다음을 실행:
- 데이터셋에서 가짜 댓글 선택
- 크롬 드라이버 창 열기
- 여론 수렴 사이트 URL 로딩
- 댓글 입력 박스에 댓글 입력
- “Finish” 버튼 클릭
- 크롬 드라이버 창 종료
- 잠시 대기(Sleep). 대기 시간은 일정 범위 내(수초~수분)에서 랜덤
- 데이터셋의 다음 가짜 댓글로 넘어간 후, 2~8번 과정 반복
※ GPT-2 모델
총 파라미터 수는 1억 2천 4백만개이며 가장 낮은 수준(기본적인 수준)의 모델을 사용했고, Temperature 파라미터는 기본값인 0.7로 고정되었습니다.
(역자 주: GPT-2에서 Temperature 파라미터는 템퍼레쳐라는 영단어 해석에서 직관적으로 알 수 있듯이 “문장의 성격, 분위기”를 의미합니다. Temperature는 볼츠만 확률 분포를 사용해 텍스트 내용의 랜덤한 정도를 결정하는 실수 파라미터이며 0에 가까울 수록 반복적이고 예측이 쉬운, 즉 뻔한 문장 패턴을 띄게 됩니다. 반대로 1에 가까울수록 더 불규칙적이고 예측불허의 문장을 만들어냅니다)
학습에 사용한 댓글의 문장 길이는 75~100 단어이며, 이는 문장 길이가 쓸데없이 길어지는 것을 막아 테스트 시에 사람들이 문장 길이를 가지고 기계가 만들었는지 분간하지 못하도록 하기 위함입니다. GPT-2 모델은 총 179,034개의 서로 다른 가짜 댓글을 생성했으며 이중 적절하다고 판단된 1,001개 댓글을 수작업으로 뽑아 테스트에 사용했습니다. (역자 주: GPT-2를 사용했지만 사람 손을 결국 탔다는 데에서 공격받을 여지가 있는 부분으로 보입니다)
학습, 모델 수정(파인튜닝), 텍스트 생성에 사용한 코드는 Max Woolf 씨에 의해 무료로 제공되며 다음 구글 Colab 사이트에서 받으실 수 있습니다:
Comments Examples
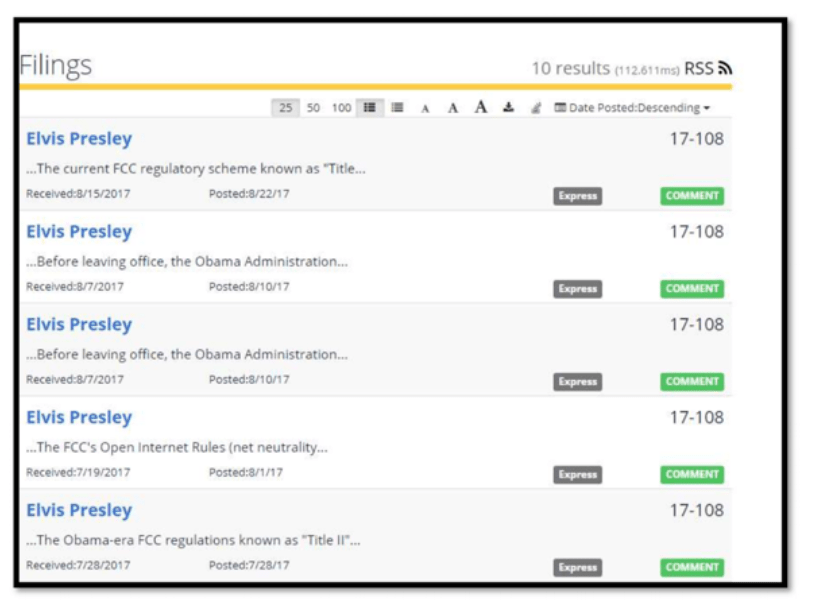
- GPT-2 모델로 생성해 여론 수렴 사이트에 올린 “가짜” 코멘트 예시
| Comment | Response ID | Date/Time | Sentiment |
| I support Governor Little’s efforts to overhaul Idaho’s Medicaid program. | 459669 | 10/27/2019 4:00:00 PM | 의료급여 수급조건 완화에 찬성 |
| Medicaid is an important safety net program. It helps people who are losing their coverage to get back on their feet. We need to make health and wellness a priority for the Medicaid program in Idaho. | 459825 | 10/27/2019 6:08:00 PM | 중립 |
| I am writing to you today regarding Idaho’s Medicaid waiver proposal, I oppose the aspects of this program that create new burdens on people who are already struggling. The proposed changes to Medicaid could deny health insurance to sick individuals when they are most in need. I do not support this approach that creates barriers to access. I am hopeful that you change the proposed waiver. | 460129 | 10/27/2019 10:36:00 PM | 의료급여 수급조건 완화에 반대 |
- 기계 댓글인데 사람이 쓴 글로 오분류된 댓글 예시
| “사람 댓글”로 잘못 분류된 “기계 댓글” | 설문조사 시 분류 성공율 |
| As a physician and health educator, I feel this is absolutely crucial to care for the poor and vulnerable in Idaho. The proposed waiver would harm the most vulnerable members of our state. It would make our state so sickly and with so many children and adults who would be affected by this waiver, this will end up costing most of the proposed budget to administer. | 0.00% |
| The work requirements are based on a false premise that everyone who qualifies for Medicaid is “lazy” or “unemployed.” In fact, work requirements are a huge waste of time and resources. The proposal is based on a false premise that the state is offering people who are working nothing but the minimum wage an additional 20 hours a week. This is a ridiculous idea. | 0.00% |
| I am very concerned about the impact these new work requirements would have on people in Idaho who are already struggling. I am a social worker and had no idea that the work requirements were being challenged and ended up costing the state more money. | 4.76% |
| Taking away health care will not promote work. The evidence from other developed countries shows that work itself actually leads to better health | 6.67% |
| The goal of Medicaid is to give coverage to those who need it. This work requirement will not accomplish this goal. | 10.00% |
| In addition, it should be noted that the working families who are eligible for Medicaid will have to pay a premium and/or copay. These are families who make minimum wage and/or don’t have resources to pay for health insurance, even if they are eligible. | 10.00% |
- 사람 댓글인데 기계가 쓴 글로 오분류된 댓글 예시
| “기계 댓글”로 잘못 분류된 “사람 댓글” | 설문조사 시 분류 성공율 |
| [ Medicade health coverage helps Idaho’s most frail and vulnerable] | 25.00% |
| [Insert Comment Here]I request your action to prevent the State of Idaho from implementing illegal work reporting requirements. | 28.57% |
| [I think Idaho should respect the will of the voters and enact expanded Medicaid without any additional requirements. | 28.57% |
| [Thank you for the opportunity to comment. I am against the work requirements for Medicaid. This requirement came on the heels of expanding Medicaid to cover the working Americans in the gap. Working Americans. These requirement are onerous and should not be allowed to take effect.] | 31.82% |
| Please disallow this constriction to healthcare delivery, extra complicated bureaucracy and greatly added wasteful expense. | 36.00% |
| Reject Medicare restrictions. | 43.75% |
| WORK REQUIREMENTS ARE ILLEGAL. | 45.83 |
| Please NO restrictions. | 47.37% |
위 2개 테이블 결과에서 사람들이 오히려 기계가 쓴 글을 더 “사람답게” 생각하는 것을 확인할 수 있습니다.
이 실험은 실제 아이다호 주 공공 정책과 관련된 여론 수렴 사이트에서 진행했기 때문에 실험이 실제 여론과 정책 결정에 미치는 영향을 최소화해야 했습니다. 따라서 연구진은 사전에 CMS( Centers for Medicare and Medicaid Services, 메디 케어 및 메디 케이드 서비스 센터: 의료 프로그램을 관리하고 주 정부와 협력하여 의료 분야를 관리하는 미국 보건 복지부 내 연방 기관)에 실험을 인가받고 고지했으며, 웹봇이 작성한 모든 댓글은 공식적으로 CMS에 의해 삭제되었습니다.
전 제가 데이터 분석을 하던 2016~2017년 경을 기준으로 한국어를 처리하고 한국어 문장을 생성하는 NLP 프레임워크는 그닥 성능이 만족스럽지 못했던 기억이 있습니다. 하지만 이 논문을 읽으면서 GPT-2가 영문장을 학습, 생성하는 수준으로 한국어 문장을 다룰 수 있는 도구가 있다면, 포털사이트와 정부 청원 사이트 등 여러 곳에서 특정한 의도를 가진 집단에 의해 여론이 “가짜”로 생성될 수도 있겠다는 생각이 들었습니다.

논문 본문에는 이를 방지하기 위해 몇 가지 방법을 제시하고는 있지만, GPT-2와 웹봇과 프록시 서버를 사용할 줄 아는 개발자라면 CAPTCHA를 비롯한 인증수단도 우회하거나 인증과정도 기계화할 수 있지 않을까요?

“2019.12월 4주 – [논문요약] DeepFake, 공공정책 결정에 개입”에 대한 한 가지 생각