잡썰을 풀며…
간간히 주간 연재물이 아닌 잡썰을 풀어보려고 합니다. 특히 오늘같이 비 오는 날에는 어쩌면 필 꽂히면 딱 쓰고 싶은 글 일지 모르겠습니다.
사실 이전 직장에서 컨텐츠 라이터로 일하면서 블로그를 운영해보라는 말을 여러 번 들었습니다만, 결국 직장 다닐 때는 귀찮아서 뒤로 하다가 직장을 그만두고 나서야 글을 쓰게 된 것 같습니다(많은 개발자 분들이 그러하듯이…).
이 블로그에 쓰는 글은 기본적으로 번역물입니다. 하지만 나름 발 한 쪽은 IT에 몸 담고 있었던 사람인 만큼 형편없는(=직역으로 틀리지 않게만 번역하는 데에만 집중하는) 논문, 블로그, 튜토리얼, 서적 번역에 고통받으며 몸서리치고 진저리났던 오랜 경험이 있습니다.
그래서 원문을 대조해보시면 알겠지만 원문의 기술적 내용 외에는 사실상 초월번역을 하거나 아예 원문 구조 자체를 재구성해서 편찬합니다. 일종의 원문을 바탕으로 한 콘텐츠 재창조이자 큐레이팅이라고 할 수 있습니다. 필요에 따라서는 순서는 물론이고 늬앙스도 바꾸며 콘텐츠 생략과 보강도 빈번하게 합니다.
물론, 이것이 가능한 이유는 제가 모든 내용을 다 이해하고 쓰고 있기 때문이며 개발하시거나 분석하시는 입장에서 쓰려고 하기 때문입니다. 이 블로그의 Target Audience는 매우 다양하므로 모두를 만족시킬 수는 없지만, 관심있는 주제가 나왔을 때에만 봐주셔서도 좋습니다. 누군가에게라도 유익이 된다면 그걸로 족하니까요.
저는 번역가이기도 하기 때문에 사실 맞춤법과 윤문에 굉장히 민감합니다. 하지만 이 블로그만큼은 맞춤법 검사를 하거나 다 작성한 초안을 2,3번 읽으면서 탈고하는 일은 일단 생략하려고 합니다. 눈에 뵈기 싫을 정도만 아니길 바랄 뿐…
어제의 Breakthrough가 오늘의 Baseline
이 블로그에서 IT와 프로그래밍 전반을 다룰 예정이지만 머신러닝으로 학위를 딴 만큼 저는 아무래도 A.I에 관심을 두게 될 수 밖에 없는 것 같습니다. 그래서 다음 주간 매거진 포스팅은 신경망이 들어가는 포스팅을 할까 합니다.
예전에 잠시 검색 엔진 회사에서 일하면서 NLP를 공부한 적이 있습니다. 그런데 그 당시 뜨던 기술이 어떻게 발전해 왔는지를 보면서 기술 발전 속도가 정말로 빠르다는 케케묵은 클리셰같은 생각이 마음에 와닿았습니다.
그 때 당시만 해도 Seq2Seq과 Attention 모델은 매우 핫한! 주제였습니다. 많이 쓰여서 핫하다기 보다는 나온지 얼마 안 된 (2014년 논문에 상용화 시기는 2015~2016 즘이었던 걸로 기억합니다) 따끈따끈한 주제였습니다.
그런데 저번 DeepFake 포스팅을 작성하면서 GPT-2라는 게 튀어나오길래 궁금한 나머지 우연히 NLP 분야의 동향을 보게되었습니다. 재미있게도 Seq2Seq+Attention 조합은 (물론 현업에서 아직 사용하고 있는 곳도 있겠지만) 최소한 학술적으로는 벤치마크용 Baseline 취급을 받는 것 같습니다.
Self-Attention, Transformer, ELMo, BERT, GPT-2 등 신기방기한 논문이 많이 나와있는데 최신 기술이 변화하는 속도가 참 빠르구나라는 생각이 들었습니다.
내친김에 Transformer에 대한 블로그 포스팅을 잠시 읽어보았는데 아키텍처가 참 희한해 보였습니다. 마치 LSTM에서 Gate Unit을 처음 접하고 이해하려고 할 때처럼 마냥 복잡해보였습니다. 속으로 그냥 RNN 계열을 쓰지 “뭐 이딴 식으로 복잡한 아키텍처를 쓸 필요가 있나?”라는 생각도 들기도 했구요!ㅎ
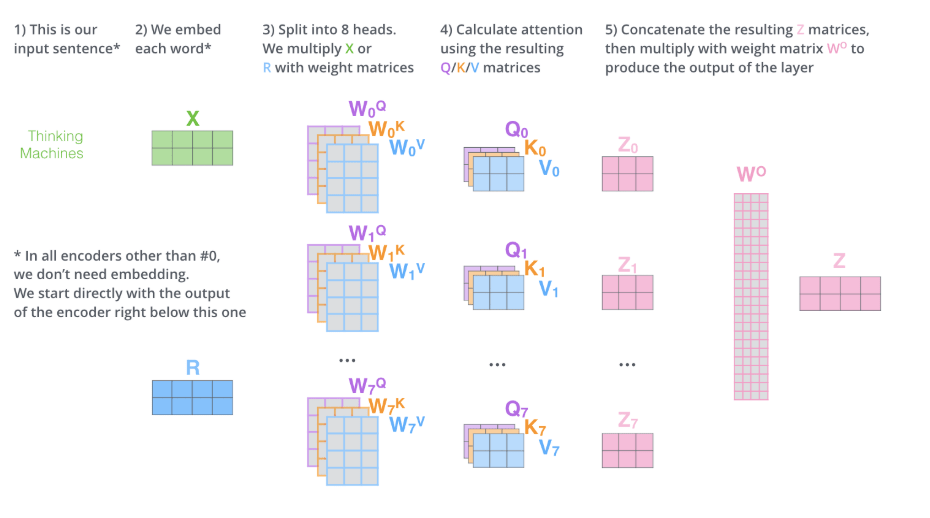
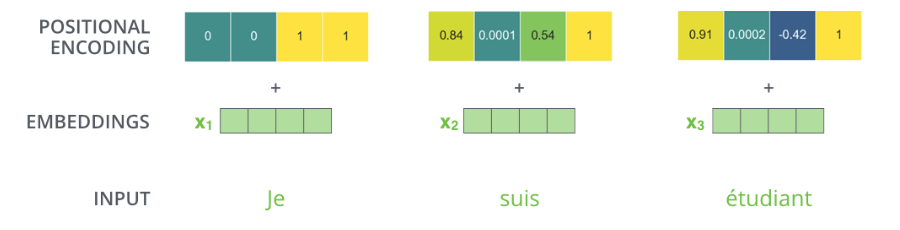
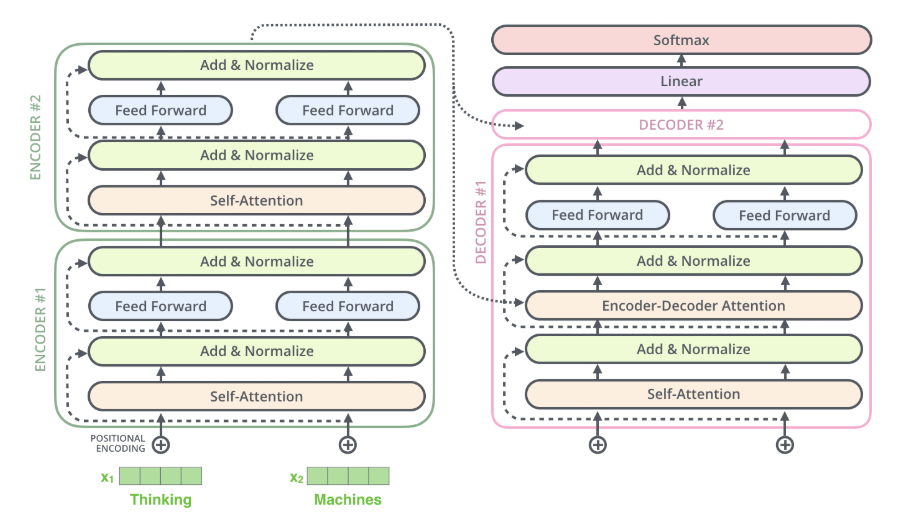
nlpinkorean이라는 사이트 운영자께서 이미 Seq2Seq+Attention과 Transformer에 대해 좋은 번역을 해주셨길래(보충/수정 제안하고 싶은 부분도 있지만) 그래서 다음 포스팅은 BERT 또는 GPT-2를 소개하는 원문 포스팅 내용을 제가 번역해서 올릴까 합니다. 사이트 운영자님께 함께 번역하자고 메일을 드렸는데 답장이 빨리 왔으면 좋겠습니다!
