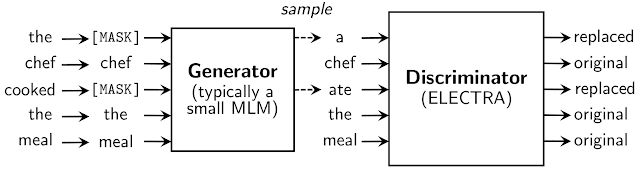
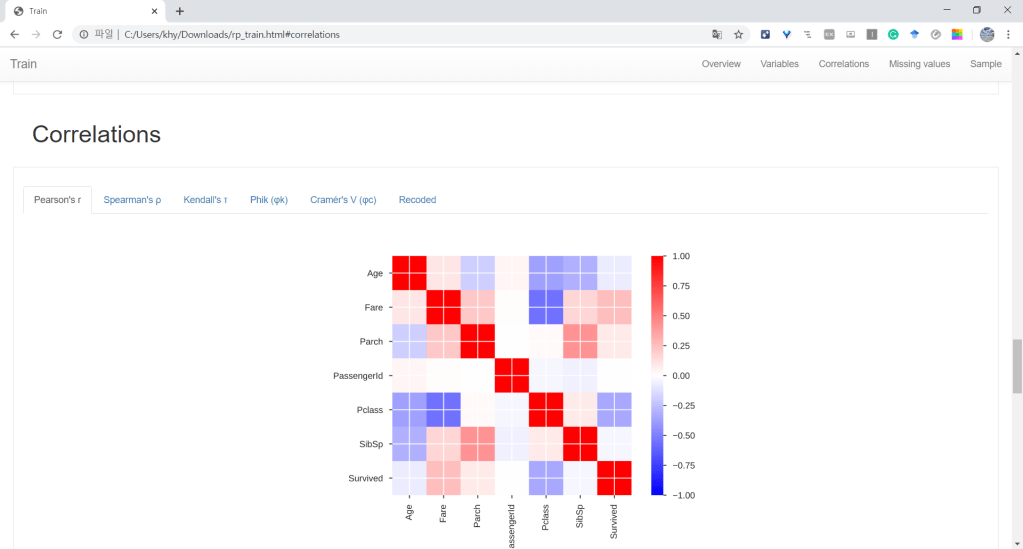
스마트 컨트랙트에는 컨트랙트에 필요한 데이터만
다른 데이터를 저장하려면 이벤트 형태로 Emit
Emit한 이벤트를 Frontend에서 Retrieve
스마트 컨트랙트에 데이터를 저장하지 말자
원제: Smart Contracts are not Databases 원작자: Alberto Cuesta Cañada (원작자분의 요청으로 출처를 명시합니다.)

들어가며
첫 글 치고는 꽤 늦었지만 4월의 화창한 봄날을 맞이하는 첫 포스팅으로 블록체인을 다룹니다. 이 번역글에서는 이더리움의 스마트 컨트랙트를 사용해 블록체인 상에 데이터를 저장하고자 할 때 유용한 개념을 소개합니다. 이더리움과 스마트 컨트랙트를 소개하려면 별도의 포스팅을 올려야 하므로 여기서는 그냥 지나갑니다. 저는 현재 카카오의 블록체인 자회사인 Ground X에서 테크니컬 라이터로 일하고 있습니다. 당분간 업무에 빨리 적응할 겸(?), 인공지능 보다는 블록체인에 대한 포스팅을 올리려고 합니다.
혹시 스마트 컨트랙트 안에 DB 테이블을 넣고 있는 사람이 있다면 분명 실수를 저지르고 있는 것일 겁니다. 제가 최근까지 그런 것 처럼 말이지요.
블록체인 솔루션을 개발하려면 데이터를 대하고 다루는 방식, 개인정보를 대하는 방식이 달라져야 합니다. 블록체인 솔루션 개발은 금전거래 기록만 가지고 화폐를 구현하고 프로그램으로 이 거래 과정을 제어한다는 점에서 그리 어렵지 않지만, 개발자가 거의 통제할 수 없는 솔루션(역자 주 – 누구나 스마트 컨트랙트를 배포할 수 있고 모든 데이터가 공개된 퍼블릭 블록체인의 속성을 뜻하는 것으로 보입니다.)을 만든다는 점에서 매우 까다롭습니다.
제가 최근까지 한 가지 놓쳤던 점은 “퍼블릭 블록체인에 올려진 데이터는 대체 무엇이냐”입니다. 트랜잭션 히스토리를 손쉽게 기록하는 메커니즘을 찾던 저는 우연찮게 매우 세련된 방법을 찾았습니다. 단, 이 과정에서 개인 정보를 다룰 때 얼마나 조심해야 하는지도 분명히 깨달았습니다.
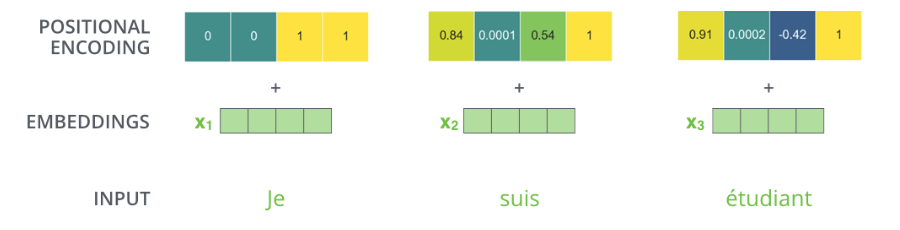
이더리움 블록체인에서, 상태 변수(State Variables)에는 오직 스마트 컨트랙트가 사용할 데이터만 저장해야 합니다. 아카이빙 하고 싶은 다른 데이터가 있다면 꼭 이벤트(Event) 형식으로 저장해야 합니다.
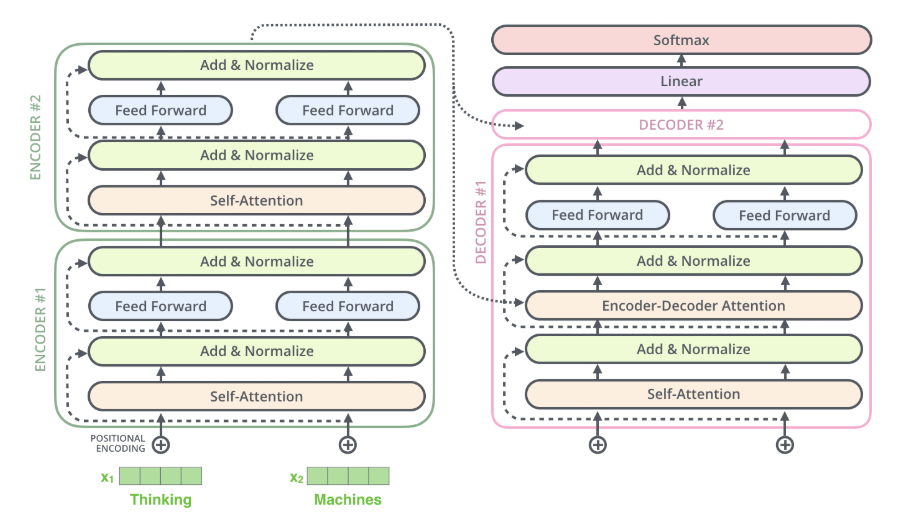
이 글에서, 저는 로우레벨 이더리움 아키텍처, 블록체인 개발 방법론, 그리고 코드 몇 줄을 사용하여 블록체인 상태를 변화시키고 이를 추적하는 방법, 스마트 컨트랙트를 더 간단히 작성하는 방법, 그리고 당신이 남의 허락 없이 타인의 데이터를 블록체인 상에 공개하고 있을 지도 모른다는 점을 보여 드리겠습니다.
데이터를 추적하는 더 좋은 방법
분산화된 금융 플랫폼은 거래 기록을 하나도 빠짐없이 제공해야 합니다. MiFID II 같은 규제는 규제 담당자가 요구할 때마다 모든 금융 기록을 제출하는 것을 의무화하고 있습니다. 이 모든 금융 기록은 단순히 토큰 전송 기록만을 의미하는 게 아니라, 사용자가 블록체인 상태를 변화시키기 위해 수행한 모든 종류의 행동 기록을 포함합니다.
저는 이렇게 블록체인 상에 기록된 모든 상태 변이 기록을 어떻게 추적할지 고민하면서 먼저 다음과 같이 생각했습니다: “모든 상태 변이는 블록체인에 기록되므로 반드시 블록들을 이동해 가면서 트랜잭션 히스토리를 얻는 방법이 있을 것이다.” 이는 모든 트랜잭션 데이터를 스마트 컨트랙트 안에 데이터 구조(Data Structure)에 우겨 넣는 것보다는 더 우아한 방법 같았습니다. 저는 여태 스마트 컨트랙트는 최대한 간단하게 작성하고 외부 도구를 최대한 많이 활용하라고 배웠기 때문입니다.
트랜잭션 히스토리 위에 만들어진 데이터베이스는 데이터가 블록체인에 담겨있기 때문에, 사용자는 어디에서든 필요할 때마다 데이터베이스를 다시 생성할 수 있습니다(역자 주 – 블록체인상에 DB가 있기 때문에 어디에서든 필요할 때마다 DB 액세스 가능함을 말함). 우리가 사용하는 스마트 컨트랙트는 데이터를 아카이브처럼 저장할 필요가 없습니다. 저는 제 능력자 친구인 Bernardo Vieira에게 이렇게 트랜잭션 히스토리에 기반한 DB를 개발하려면 어떤 도구를 써야 하는지 알려달라고 졸랐습니다. 그는 누가 무엇을 해야 하는지 알 만한 사람이기도 하고 보통 쓸 만한 것들을 가르쳐주곤 합니다.
저는 Bernardo가 저를 다시 찾아와 “블록체인에서 발생한 이벤트를 기록하는 것은 어떤가? 이러면 자네 문제가 해결된 건가?”라고 묻기 전까지는 이벤트에 대해 생각조차 하지 못했습니다.
이벤트, 그것이 답이었습니다. 머릿속이 새롭게 열어졌습니다.
이벤트 사용하기
그 때까지만 해도 저는 이더리움 이벤트에 관해 별 관심이 없었습니다. 물론 블록체인 상태를 변화시키는 것은 어떤 값을 리턴 받는 게 아니라 어떤 이벤트를 발생시키는 것인줄은 알고 있었습니다. 또 그런 이벤트를 프론트엔드단(Frontend Layer)에서 캡처해 원하는 데이터를 뽑아내는 법을 이미 알고 있었고, 그렇게 얻은 데이터를 잘 활용해왔습니다. 하지만 정작, 어떤 이벤트가 어떤 역할을 하는지 몰랐습니다.
스마트 컨트랙트에서 이벤트를 발생시키면 이벤트는 블록체인상에 반정형(semi-structured) 포맷으로 기록됩니다. 이벤트의 몇몇 컬럼은 항상 동일한 값을 지니며 스마트 컨트랙트에서 사용자가 이벤트를 다룰 때 정의한 변수들이 나머지 컬럼 값을 구성합니다. 이벤트는 가스 비용 측면에서 이더리움 블록체인에서 가장 저렴한 연산 중 하나입니다. 4000 가스(이더리움의 트랜잭션 비용)면 정말 싼 거죠.
초기에는 TheGraph를 사용해 블록체인에서 발생한 이벤트에 접근하려고 했습니다. 이 툴은 블록체인 이벤트를 캡처해 GraphQL 인터페이스로 이 이벤트들을 쿼리하도록 합니다. 이 방법은 저희 케이스에서는 결과적으로 너무 복잡한 방법이지만, 덕분에 쿼리를 좀 날려보면서 블록체인 이벤트는 쓰기-전용(write-only) 데이터베이스임을 이해할 수 있었습니다. 어떤 컬럼들은 모든 이벤트에서 동일하며 사용자가 원하는 값을 이벤트에 쓰기 위한 사용자 컬럼을 정의할 수 있습니다.
그러면 어떻게 블록체인 이벤트를 쿼리해야 할까?
블록체인 이벤트가 동작하는 원리는 그 자체로는 어려운 개념이 아니지만, 저희가 이벤트 쿼리를 위한 솔루션을 개발하는 과정에 매우 큰 영향을 미쳤습니다. 저희가 맞이한 첫 번째 변화는 저희가 지금에서야 제대로 이해하게 된 다음의 개발 원칙을 받아들이는 것이었습니다:
모든 상태 변화는 반드시 이벤트를 만든다.
모든 상태 변화에는 이벤트가 뒤따르기 때문에 저희는 트랜잭션을 추적하는 데 신경쓰지 않아도 됩니다. 모든 상태 변화는 이벤트를 발생시키고 그저 프론트엔드에서 이벤트 정보를 추출하는 도구를 입맛대로 골라쓰면 됩니다.
그런데 이 과정에서 개인 정보는 어떻게 보호될까요? 제가 쿼리할 때마다 민감한 개인 정보를 포함한 모든 데이터를 받게 됨을 걱정해야 할까요? 글쎄요, 어차피 모든 데이터는 트랜잭션 데이터만 있으면 접근이 가능하니까, 저는 그저 블록체인 이벤트에 더 쉽게 접근할 수 있는 방법을 찾은 것 뿐이지요.
기억하시죠? 퍼블릭 블록체인에 있는 모든 데이터는 누구에게나 공개되어 있습니다.
제 다른 글을 읽어보셨다면 저는 항상 일을 가장 간단한 방법으로 해결하기를 좋아합니다(저도요…복잡한 것은 정말 싫습니다). 지금까지, 저는 단순히 블록체인에 문서를 저장하는 일 정도는 밑에서 소개할 코드 라인 수준에서 만족해왔습니다.
pragma solidity ^0.5.10;
contract DocumentRegistry {
event Registered(uint256 hash);
mapping (uint256 => uint256) documents;
function register(uint256 hash) public {
documents[hash] = msg.sender;
emit Registered(hash);
}
function verify(uint256 hash) public view returns (uint256) {
return documents[hash];
}
}이 정도면 충분히 간단한 코드이지만, 여기서 더 간단하고 효율적으로 만들 수도 있습니다.
pragma solidity ^0.5.10;
contract DocumentRegistry {
event Registered(uint256 hash, address sender);
function register(uint256 hash) public { emit Registered(hash, msg.sender); }
} 두 번째 컨트랙트 코드는 보시다시피 내부에 아무 것도 저장하지 않고 데이터를 추출하는 함수도 없습니다. 그럼에도, 첫 번째 컨트랙트와 동일한 일을 수행합니다.
(역자 주 – 스마트 컨트랙트로 register 함수를 실행하면 Registered 이벤트를 발생시켜 데이터를 블록체인에 저장하며 Registered 이벤트의 입력 파라미터로 사용자가 저장하고 싶은 정보인 msg.sender를 이 데이터를 retrieve할 수 있는 key값인 hash값과 함께 넘겨주어 블록체인 상에 기록하는 것으로 보입니다)
보통 이벤트는 잠깐 생성되었다가 사라진다고 생각하곤 하는데 블록체인에는 이벤트를 포함해 모든 것이 영구적으로 남아있습니다. 만약 당신이 블록체인 상에 존재하는 어떤 문서가 진본인지 확인하고 싶다면 (혹은 위/변조가 없는지 확인하고 싶다면), 그저 문서를 생성한 트랜잭션의 해쉬값을 계산한 다음 캐쉬에 쿼리를 날리면 됩니다. 한 가지 신경써야 할 것은 외부 인프라를 사용해 이벤트를 추적하고 블록체인 상태를 오프체인(체인에서 분리된 오프라인 상태)에서 복제해야 한다는 점입니다. 지금까지 소개한대로 블록체인에 데이터를 DB처럼 쓰고 읽는 방식은 같은 목적을 이루기 위한 다른 방법보다 상대적으로 쉬울 뿐 아니라 퍼포먼스 측면에서도 가장 좋다고 생각합니다. starter-kit에 방문하시면 sample event cache를 찾을 수 있습니다. 이 항목에는 저희의 모든 프로젝트에서 사용하는 도구가 있으며 빠르게 개선되고 있습니다.
결론
이 방법을 개발하면서 꽤나 큰 인식의 전환이 이루어졌기에 갑자기 제 머릿속에서는 “스마트 컨트랙트 내부에 데이터 구조를 구현해야 해.”와 “그냥 이벤트 발생시키고 나머진 잊어버려.”로 생각이 분명히 나뉘어졌습니다. 스마트 컨트랙트가 데이터를 필요로 한다면 상태 변수(State Variable)에 데이터를 저장하시고 그렇지 않다면 이벤트 형태로 내보내십시오. 저는 평상시에 어떤 블록체인 솔루션이든 전체 코드의 약 10%만이 스마트 컨트랙트 코드라고 말해왔습니다. 또 트랜잭션을 제대로 추적하는 솔루션이라면 10% 미만에 그칠 것입니다. 이제, 저희는 앞으로 몇 개월 정도 지금까지 이 글에서 설명한 내용과 자체 개발한 도구를 활용해 스마트 컨트랙트를 개발할 것입니다. 이 리포지터리에서 개발을 진행하고 있으니 궁금하신 분들은 오셔서 저희의 스마트 컨트랙트와 툴을 구경하세요.